3 Considerações conceituais
Alguns cuidados
A coleta de dados deve considerar a área de análise. Dessa forma, a inlfuencia do da escala será reduzida.
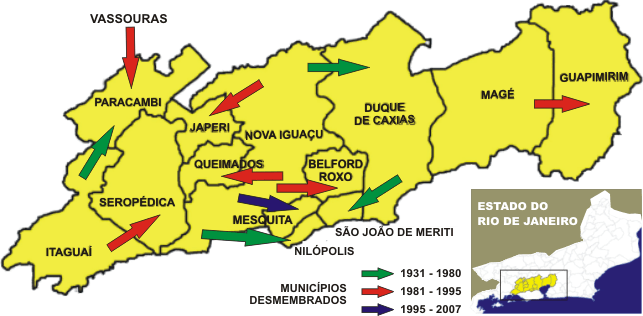
E quando se trata de análise temporal temos que tomar cuidado com o fato de que as áreas poderão ter sido alteradas com o passar do tempo. Para solucionar isso, se usa as áreas mínimas comparáveis (AMCs).
Por exemplo:
3 Considerações conceituais
3.2 Vizinhança
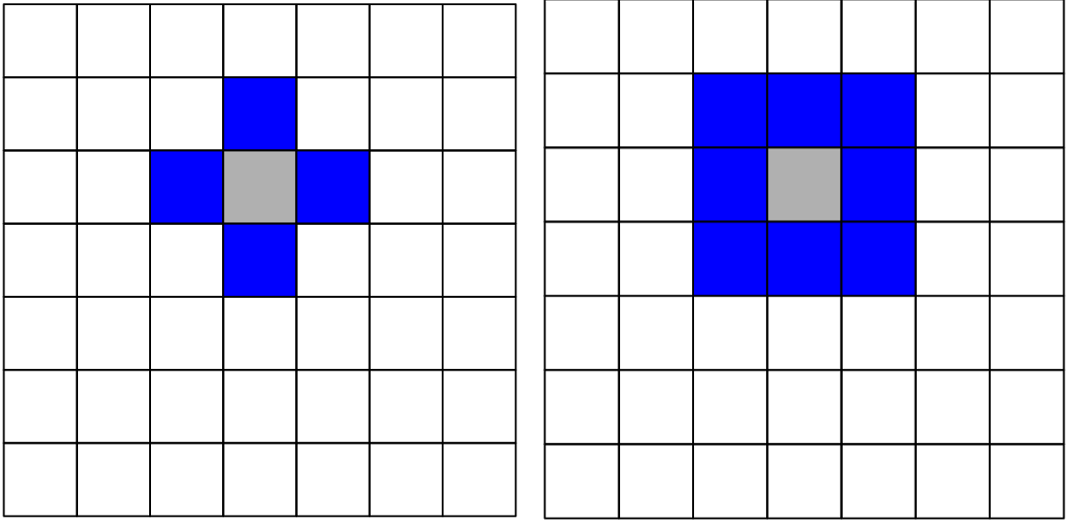
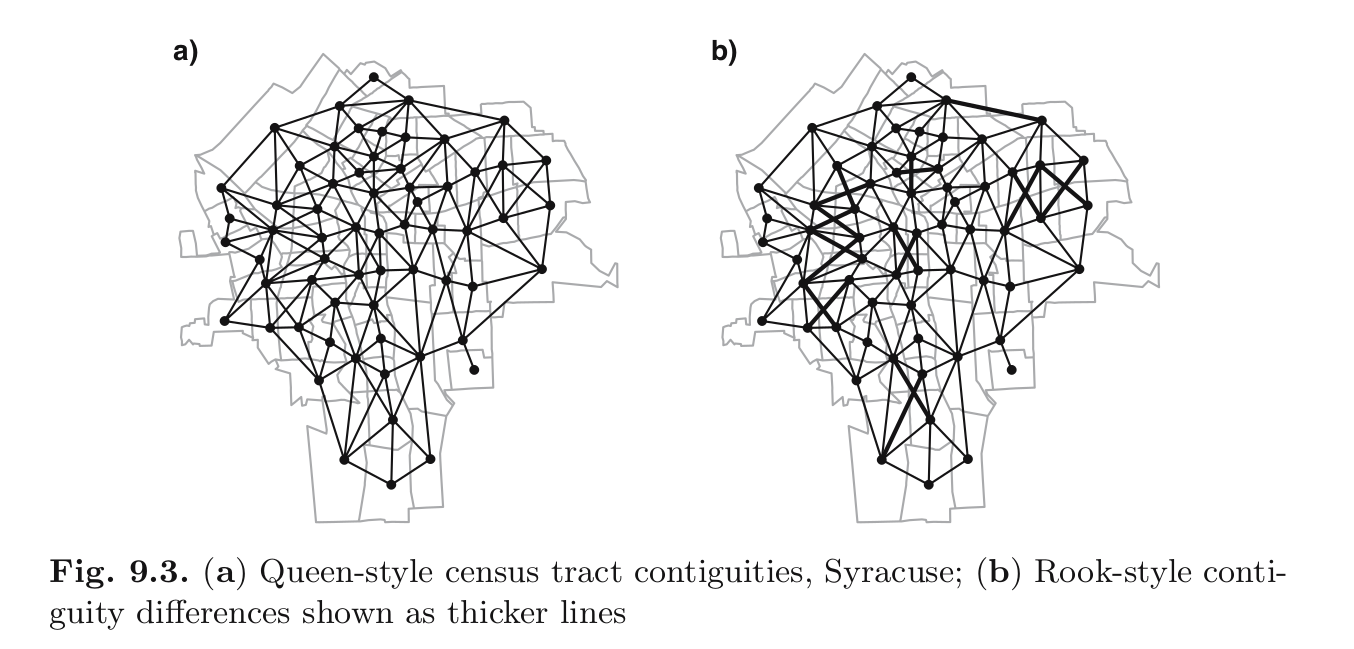
A definição de vizinhança é fundamental nesse tipo de análise, e deve ser considerado a natureza do fenômeno de estudo na definição do mesmo, já que há várias formas de definir os polígonos vizinhos:
- Por contiguidade;
- Queen case;
- Rook case;
3 Considerações conceituais
3.2 Vizinhança
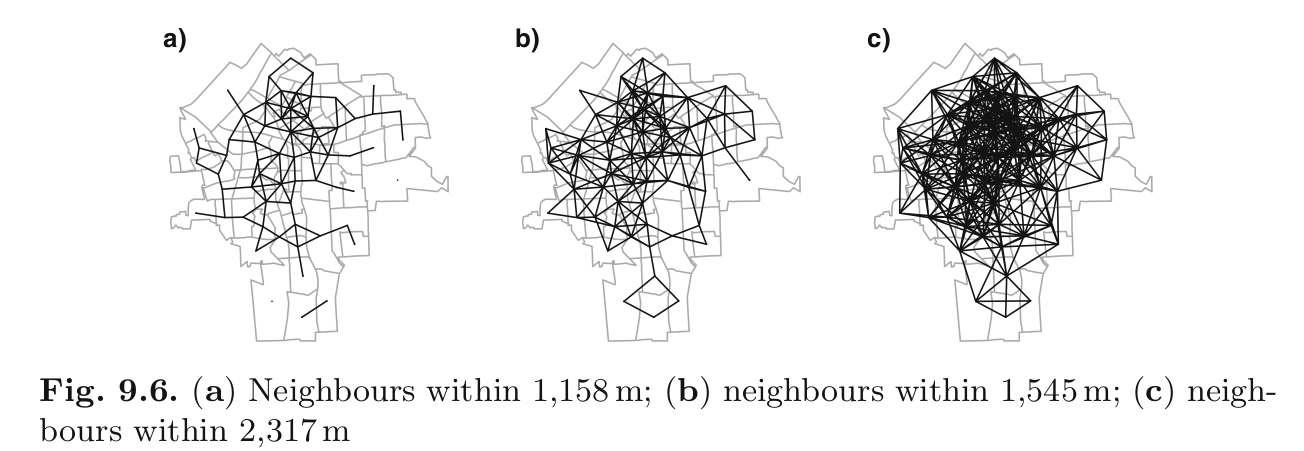
K vizinhos mais próximos
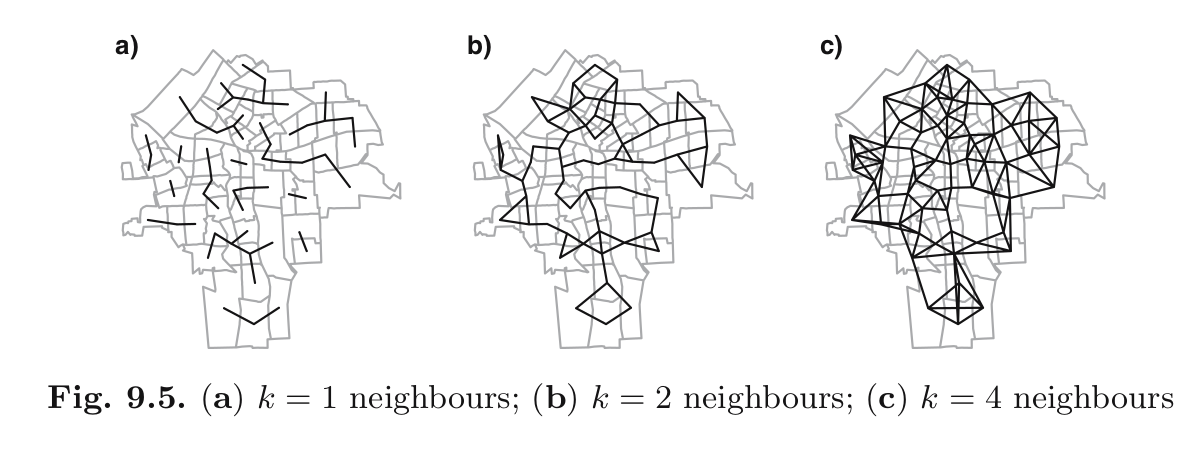
3 Considerações conceituais
3.2 Vizinhança
Uma vez definido o conceito de vizinhança a ser utilizado, pode-se construir a matriz de vizinhança, também chamada matriz de proximidade espacial ( ). Que estão será usada na análise de correlação espacial.
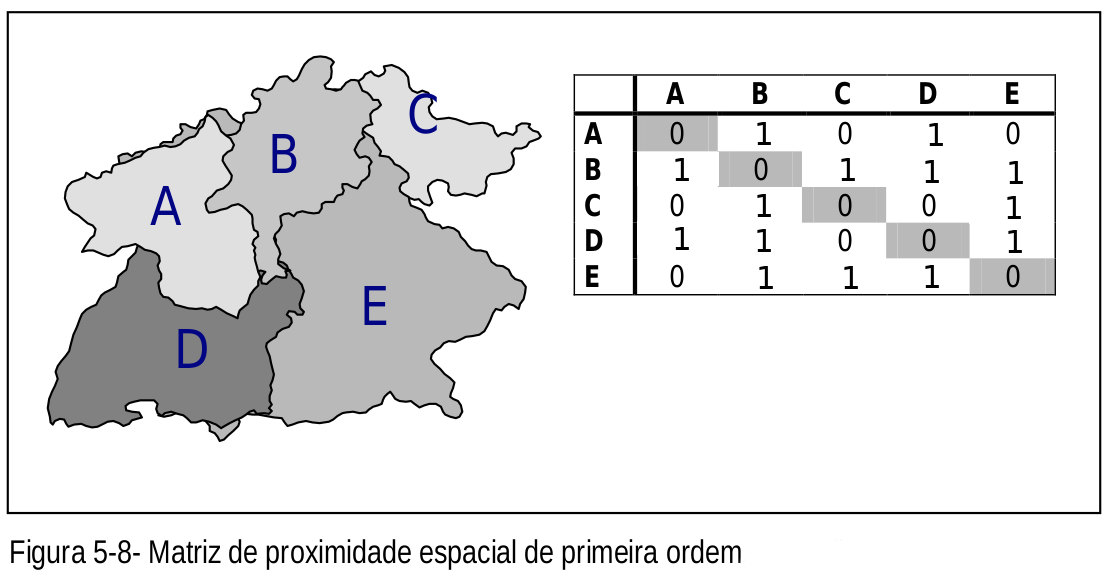
Fonte: Adaptado de Câmara et al.
Há a possibilidade de considerar vizinhança de segunda ou maiores ordens.
Um ponto a considerar é com relação aos polígonos que estejam no limite da área de estudo que, em geral terão menos polígonos vizinhos e com isso induzir a um viés de super ou sub estimação da correlação espacial.
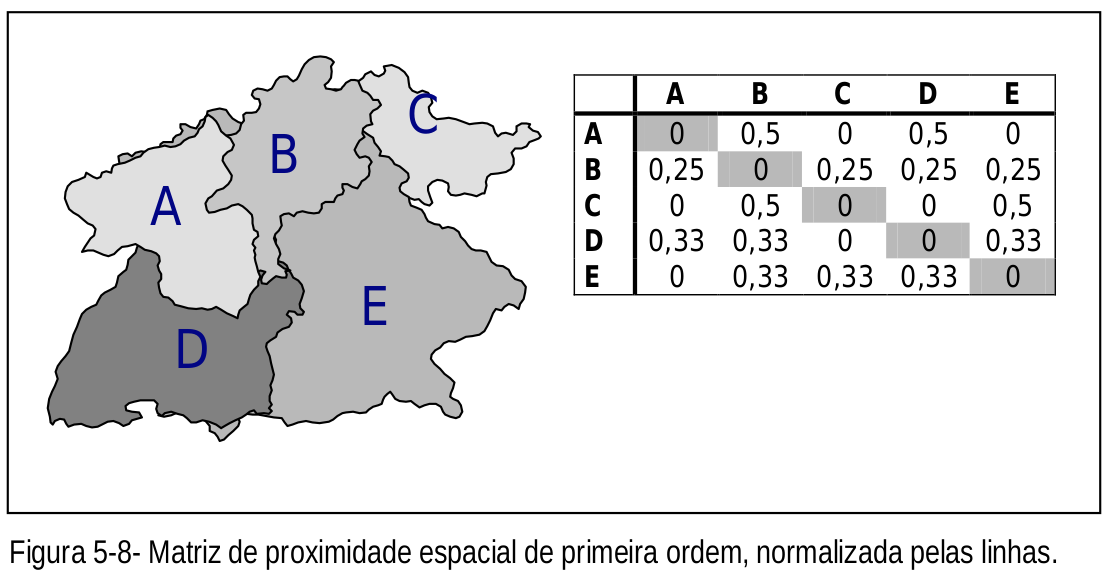 Fonte:
Fonte: 4 Processamento de dados
group_by()
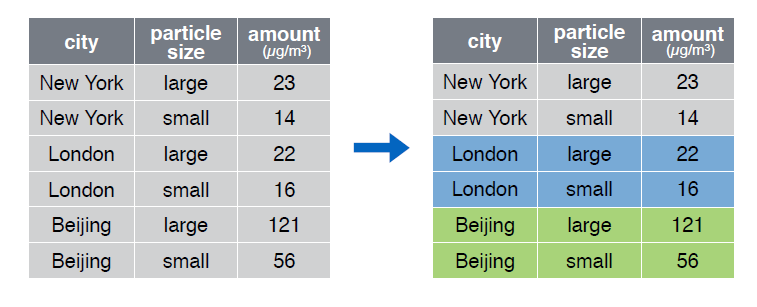
4 Processamento de dados
summarise()
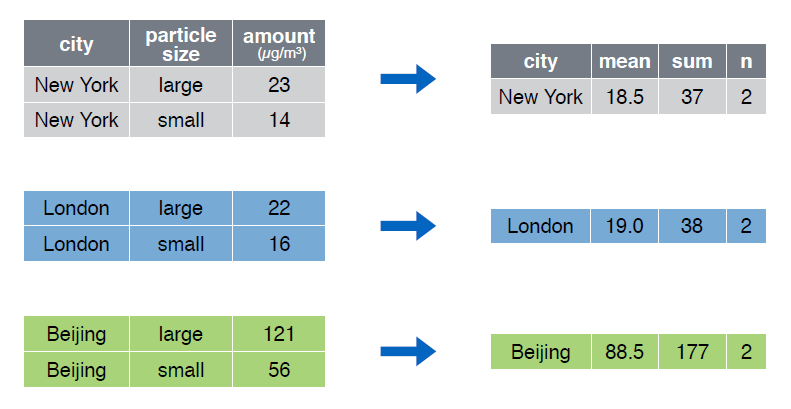
Essas funoes serão usadas para calcular o total de votos válidos de cada município e, em seguida, calcular o percentuald e votos a cada candidato.
O Pulo do gato
O que é de fato o Moran I?
pt <- municipios %>% group_by(code_muni) %>% filter(NUMERO_CANDIDATO == 13)nb <- poly2nb(pt, queen=TRUE, row.names = pt$name_muni) lw <- nb2listw(nb, style="W", zero.policy=TRUE) pt$lag <- lag.listw(lw, pt$perc_vote)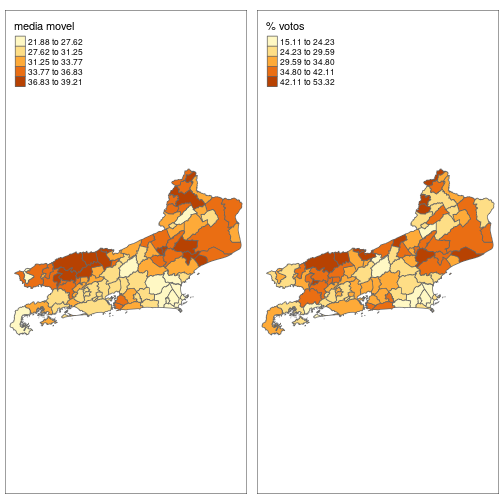
O Pulo do gato
plot(pt$lag, pt$perc_vote)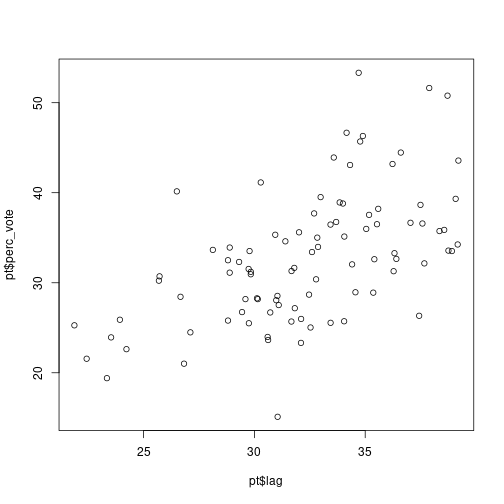
Considerações finais (5 min)
Próxima Live (25/08):
We R Live 14: Live com professor Jorge Kazuo Yamamoto
